


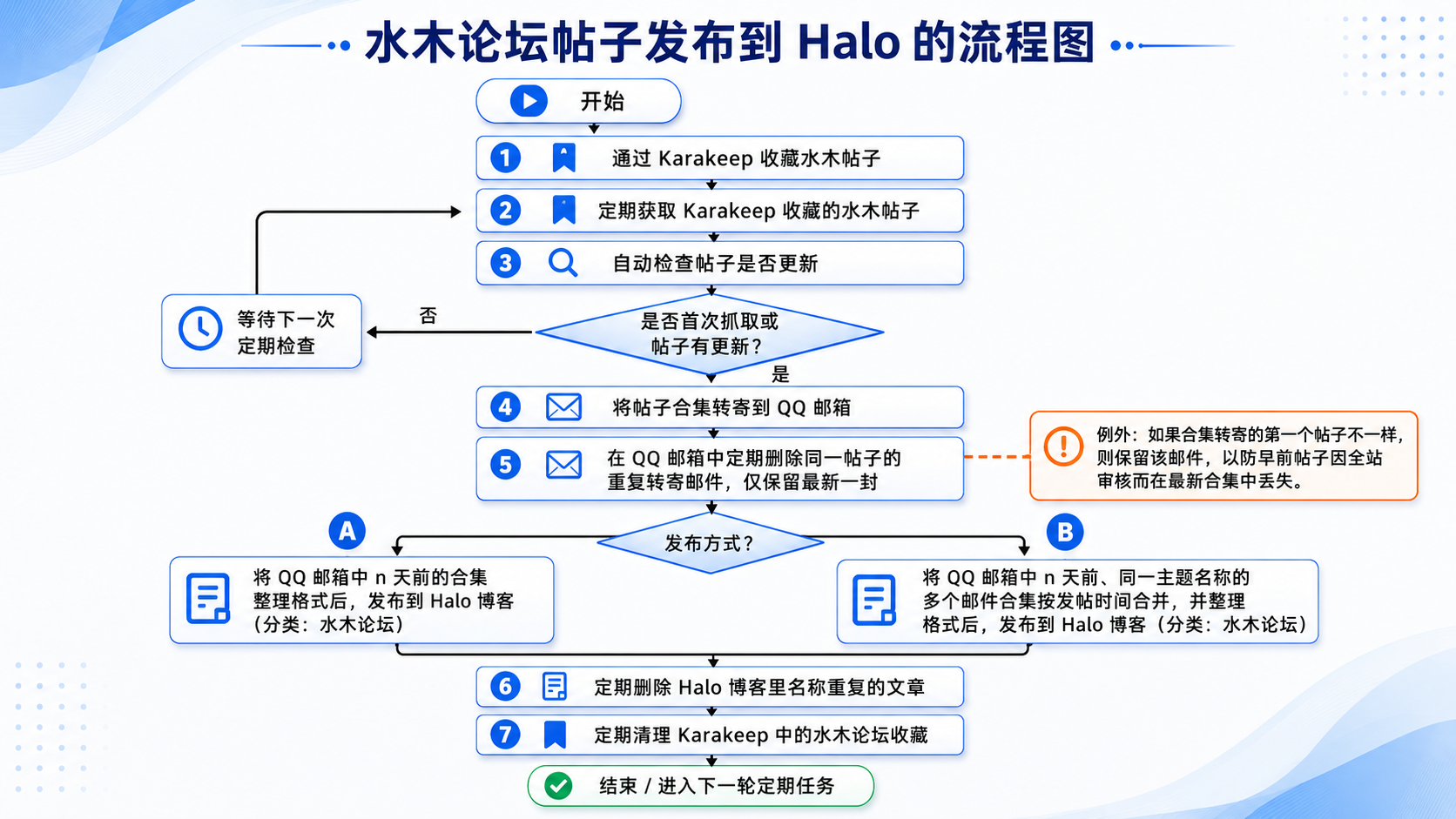
通过Karakeep收藏水木帖子 - 定期获取karakeep收藏的水木帖子并自动检查帖子是否更新,如果第一次或者将合集转寄到QQ邮箱 - 在QQ邮箱中定期删除同一个帖子的重复转寄邮件只留最新的一个(如果合集转寄的第一个帖子不一样则保留,以防止早前的帖子出现全站审核时,最新的转寄合集丢失早前帖子信息) - 将QQ邮箱中n天前的合集整理格式后发布到Halo博客(水木论坛分类)或者 将QQ邮箱中n天前的同一主题名称的多个邮件合集按发帖时间合并整理格式后发布到Halo博客(水木论坛分类)- 定期删除Halo博客里的名称重复的文章 - 定期清理Karakeep中的水木论坛收藏。
Debian12环境配置
要在 Debian 12 上运行下面这几个 Python 脚本,需要安装几个非 Python 标准库的第三方依赖。
由于使用的是 Debian 12 (Bookworm),系统默认启用了 PEP 668 保护(标记为 externally-managed-environment)。这意味着不能直接使用 pip install 在全局环境中安装包,否则会报错。
最标准且安全的做法是在你的 /root/data 目录中创建一个 Python 虚拟环境(venv)来安装这些依赖。
1. 需要安装的第三方依赖列表
除了 Python 内置的标准库(如 os, re, json, datetime, email, imaplib 等),需要安装以下第三方库:
requests: 用于处理 HTTP 请求。beautifulsoup4(代码中为bs4): 用于解析 HTML 网页内容。pycryptodomex(代码中为Cryptodome): 用于 AES 解密 Cookie 数据。imapclient: 用于简化的 IMAP 邮箱连接和操作。rich: 用于在终端输出带有颜色和格式的表格与文本。
2. 安装命令与步骤 (推荐:使用虚拟环境)
步骤 1:安装虚拟环境工具 Debian 12 默认可能没有安装 venv 模块,需要先通过 apt 安装:
apt update
apt install python3-venv -y步骤 2:进入你的工作目录并创建虚拟环境
cd /root/data
python3 -m venv venv步骤 3:激活虚拟环境并安装依赖
# 激活虚拟环境 (你会看到命令行提示符前面多了一个 (venv))
source venv/bin/activate
# 升级 pip 并安装所有需要的依赖包
pip install --upgrade pip
pip install requests beautifulsoup4 pycryptodomex imapclient rich3. 如何运行你的脚本
在使用虚拟环境的情况下,你有两种方式运行脚本:
方式 A:激活环境后运行(适合手动执行)
确保你已经执行了 source /root/data/venv/bin/activate,然后直接运行:
python halo_duplicates.py方式 B:直接调用虚拟环境中的 Python 解释器(适合 Crontab 定时任务)
无需激活环境,直接使用虚拟环境里的 Python 绝对路径来执行脚本:
/root/data/venv/bin/python /root/data/halo_duplicates.py4.备选方案 (不推荐但快捷)
如果你不想使用虚拟环境,执意要安装在系统的全局环境中,可以通过添加 --break-system-packages 参数来强制覆盖 Debian 12 的限制(注意:这可能会破坏系统自带的 Python 依赖),使用这种方法后,你可以直接用 python3 脚本名.py 来运行它们:
pip install requests beautifulsoup4 pycryptodomex imapclient rich --break-system-packages1. 获取Karakeep中的水木论坛帖子并转寄到QQ邮箱
注意:MAX_HISTORY_RECORDS 为VPS本地记录的转寄帖子的限制数量,程序会在VPS本地生成
forwarded_karakeep.txt文件,里面记录了帖子网址和最后回复时间,用于比较当前水木帖子和已经转寄帖子是否更新,如果最后回复时间不一样则再次发起合集转寄。MAX_FETCH_COUNT = 30 # 表示每次任务最多处理的最新有效书签数量。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import re
import sys
import time
import json
import base64
import hashlib
import logging
import requests
from datetime import datetime
from bs4 import BeautifulSoup
from Cryptodome.Cipher import AES
from Cryptodome.Util.Padding import unpad
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# ================= 配置区域 =================
# 1. KaraKeep 配置
KARAKEEP_URL = "http://3.9.3.8:3030"
KARAKEEP_API_KEY = "ak2_d80fab02dcf9bb166"
# 2. CookieCloud 配置
CC_URL = "http://6.6.7.6:3000/cookiecloud"
CC_UUID = "fbUpmXrhd673VhcFG"
CC_PASSWORD = "sqjrxKw8DjHgF"
# 3. 转寄与记录配置
TARGET_EMAIL = "8785@qq.com"
HISTORY_FILE = "forwarded_karakeep.txt"
MAX_HISTORY_RECORDS = 100
# 4. 获取数量配置 [新增]
MAX_FETCH_COUNT = 30 # 自定义选项:每次任务最多处理的最新有效书签数量
# ================= 全局常量 =================
BASE_URL = "https://m.newsmth.net"
HEADERS = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
}
# 预编译正则表达式
RE_FORWARD_LINK = re.compile(r'/article/[^/]+/forward/\d+')
RE_TIME_FORMAT = re.compile(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}')
# ================= 日志配置 =================
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
logger = logging.getLogger(__name__)
# ================= 核心功能 =================
def create_robust_session() -> requests.Session:
"""创建带有自动重试机制的强健 Session(全局复用),支持 POST 429 重试"""
session = requests.Session()
retry = Retry(
total=5,
backoff_factor=2,
status_forcelist=[429, 500, 502, 503, 504],
allowed_methods=["HEAD", "GET", "PUT", "DELETE", "OPTIONS", "TRACE", "POST"]
)
adapter = HTTPAdapter(max_retries=retry)
session.mount('http://', adapter)
session.mount('https://', adapter)
return session
def fetch_and_decrypt_cookies(session: requests.Session) -> dict:
"""从 CookieCloud 获取水木社区的 Cookie"""
logger.info("正在连接 CookieCloud 获取验证信息...")
req_url = f"{CC_URL}/get/{CC_UUID}"
try:
response = session.post(req_url, json={"password": CC_PASSWORD}, timeout=10)
response.raise_for_status()
data = response.json()
except requests.exceptions.RequestException as e:
logger.error(f"连接 CookieCloud 失败: {e}")
sys.exit(1)
cookie_data = data.get("cookie_data")
if not cookie_data:
logger.error("CookieCloud 返回的数据为空,请检查 UUID 或服务端同步状态。")
sys.exit(1)
if isinstance(cookie_data, dict):
all_cookies = cookie_data
elif isinstance(cookie_data, str):
try:
key = hashlib.md5(CC_PASSWORD.encode('utf-8')).hexdigest().encode('utf-8')
iv = key[:16]
cipher = AES.new(key, AES.MODE_CBC, iv)
encrypted_bytes = base64.b64decode(cookie_data)
decrypted_bytes = unpad(cipher.decrypt(encrypted_bytes), AES.block_size)
all_cookies = json.loads(decrypted_bytes.decode('utf-8'))
except Exception as e:
logger.error(f"Cookie 数据解密失败: {e}")
sys.exit(1)
else:
logger.error("获取到的 Cookie 数据格式异常。")
sys.exit(1)
pw_cookies = {}
for domain, cookies_list in all_cookies.items():
if 'newsmth.net' in domain:
for c in cookies_list:
pw_cookies[c["name"]] = c["value"]
if not pw_cookies:
logger.error("数据提取完毕,但未找到 newsmth.net 的关联 Cookie。")
sys.exit(1)
return pw_cookies
def verify_smth_connection_and_cookie(session: requests.Session) -> bool:
"""提前验证水木服务器连通性及 Cookie 状态"""
logger.info("正在验证水木社区服务器连通性及 Cookie 状态...")
try:
resp = session.get(BASE_URL, headers=HEADERS, timeout=10)
resp.raise_for_status()
if 'id="TencentCaptcha"' in resp.text or "用户登录" in resp.text:
logger.error("水木社区连通正常,但 Cookie 可能已失效(检测到未登录特征),请更新 CookieCloud!")
return False
logger.info("连通性测试通过,Cookie 状态有效。")
return True
except requests.exceptions.RequestException as e:
logger.error(f"水木社区服务器当前无法访问或不稳定,停止本次任务。详情: {e}")
return False
def load_history() -> dict:
history = {}
if not os.path.exists(HISTORY_FILE):
return history
try:
with open(HISTORY_FILE, "r", encoding="utf-8") as f:
for line in f:
parts = line.strip().split(',', 1)
if len(parts) == 2:
history[parts[0]] = parts[1]
except IOError as e:
logger.warning(f"读取历史记录文件失败: {e}")
return history
def save_history(history_dict: dict):
history_items = list(history_dict.items())[-MAX_HISTORY_RECORDS:]
try:
with open(HISTORY_FILE, "w", encoding="utf-8") as f:
for url, last_time in history_items:
f.write(f"{url},{last_time}\n")
except IOError as e:
logger.error(f"写入历史记录文件失败: {e}")
def extract_best_title(bookmark_data: dict) -> str:
explicit_title = bookmark_data.get("title")
if explicit_title and str(explicit_title).strip():
return str(explicit_title).strip()
content = bookmark_data.get("content", {})
if isinstance(content, dict):
content_title = content.get("title")
if content_title and str(content_title).strip():
return str(content_title).strip()
html_data = content.get("html", {})
if isinstance(html_data, dict):
html_title = html_data.get("title")
if html_title and str(html_title).strip():
return str(html_title).strip()
return "无标题"
def get_karakeep_bookmarks(session: requests.Session) -> list:
"""获取 KaraKeep 书签,支持设置最大获取数量"""
endpoint = f"{KARAKEEP_URL}/api/v1/bookmarks/search"
api_headers = {"Authorization": f"Bearer {KARAKEEP_API_KEY}", "Content-Type": "application/json"}
parsed_bookmarks = []
seen_urls = set()
page = 1
max_pages = 20
offset = 0
cursor = None
try:
while page <= max_pages:
params = {
"q": "newsmth.net",
"limit": 20,
"sortOrder": "desc",
"page": page,
"offset": offset
}
if cursor:
params["cursor"] = cursor
response = session.get(endpoint, headers=api_headers, params=params, timeout=10)
response.raise_for_status()
data = response.json()
bookmarks = data.get("bookmarks", [])
if not bookmarks:
break
new_items_count = 0
for bm in bookmarks:
title = extract_best_title(bm)
url = bm.get("content", {}).get("url", "")
original_url = url
if original_url in seen_urls:
continue
seen_urls.add(original_url)
new_items_count += 1
# --- 链接清洗逻辑 ---
if url.startswith("http://"):
url = url.replace("http://", "https://", 1)
url = url.replace("https://www.newsmth.net/nForum/#!article", "https://m.newsmth.net/article")
url = url.replace("https://www.newsmth.net/article", "https://m.newsmth.net/article")
if url.startswith("https://m.newsmth.net/article"):
parsed_bookmarks.append({"title": title, "url": url})
# [新增] 熔断机制:达到用户设定的数量,立即结束拉取
if len(parsed_bookmarks) >= MAX_FETCH_COUNT:
logger.info(f"已达到设定的最大获取数量上限 ({MAX_FETCH_COUNT}),停止后续 API 拉取。")
return parsed_bookmarks
else:
logger.debug(f" [-] 忽略非帖子/不合规链接: [{title[:15]}...] -> {original_url}")
next_cursor = data.get("nextCursor") or data.get("cursor") or data.get("next_cursor")
if new_items_count == 0:
break
if next_cursor:
cursor = next_cursor
offset += len(bookmarks)
page += 1
logger.info(f"KaraKeep API 历经 {page - 1} 次分页拉取,清洗后共得到 {len(parsed_bookmarks)} 个有效的水木帖子。")
except requests.exceptions.RequestException as e:
logger.error(f"请求 KaraKeep API 失败: {e}")
sys.exit(1)
return parsed_bookmarks
def process_and_forward(session: requests.Session, item: dict, history: dict) -> bool:
original_url = item["url"]
title = item["title"]
clean_url = original_url.split('?')[0]
last_page_url = f"{clean_url}?p=100"
try:
resp = session.get(last_page_url, headers=HEADERS, timeout=15)
resp.raise_for_status()
soup = BeautifulSoup(resp.text, 'html.parser')
forward_links = soup.find_all('a', href=RE_FORWARD_LINK)
if not forward_links:
return False
last_forward_a = forward_links[-1]
forward_url = BASE_URL + last_forward_a['href']
last_li = last_forward_a.find_parent('li')
last_reply_time = "1970-01-01 00:00:00"
if last_li:
time_match = RE_TIME_FORMAT.search(last_li.get_text())
if time_match:
last_reply_time = time_match.group(0)
recorded_time = history.get(clean_url, "")
if recorded_time and last_reply_time <= recorded_time:
return False
logger.info(f"触发转寄 -> {title} (时间 {recorded_time or '无记录'} => {last_reply_time})")
time.sleep(1.5)
payload = {"target": TARGET_EMAIL, "threads": "on", "submit": "转寄"}
post_resp = session.post(forward_url, data=payload, headers=HEADERS, timeout=10)
if "操作成功" in post_resp.text or post_resp.status_code == 200:
logger.info(f"推送成功 -> {TARGET_EMAIL}")
history.pop(clean_url, None)
history[clean_url] = last_reply_time
return True
else:
logger.warning(f"转寄请求失败,返回状态码: {post_resp.status_code}")
return False
except requests.exceptions.RequestException as e:
logger.error(f"网络请求异常 [{title[:15]}...]: {e}")
return False
except Exception as e:
logger.error(f"解析异常 [{title[:15]}...]: {e}")
return False
def main():
logger.info("=" * 60)
logger.info("启动 KaraKeep 水木合集自动转寄任务")
session = create_robust_session()
smth_cookies = fetch_and_decrypt_cookies(session)
requests.utils.add_dict_to_cookiejar(session.cookies, smth_cookies)
if not verify_smth_connection_and_cookie(session):
logger.info("=" * 60)
sys.exit(1)
history = load_history()
bookmarks = get_karakeep_bookmarks(session)
logger.info("=" * 60)
logger.info(f"=== 即将处理以下 {len(bookmarks)} 个有效书签 ===")
for idx, item in enumerate(bookmarks, 1):
logger.info(f"[{idx:02d}] {item['title']}")
logger.info(f" -> {item['url']}")
logger.info("=" * 60)
forward_count = 0
for item in bookmarks:
if process_and_forward(session, item, history):
forward_count += 1
time.sleep(2)
save_history(history)
logger.info("-" * 60)
logger.info(f"任务结束:本次共新增或更新了 {forward_count} 份合集。")
logger.info("=" * 60)
if __name__ == "__main__":
os.chdir(os.path.dirname(os.path.abspath(__file__)) or '.')
main()
2. 检查QQ邮箱中和水木论坛相关的合集转寄邮件,同一帖子只保留最新的合集转寄邮件
删除标题一样的水木合集转寄邮件。
注意:如果合集邮件中的第一个帖子内容不一样则都保留。
import email
import re
from email.header import decode_header
from email.utils import parsedate_to_datetime
from datetime import datetime
from imapclient import IMAPClient
from rich.console import Console
from rich.table import Table
from rich.text import Text
from rich.prompt import Confirm
# ================= 配置信息 =================
IMAP_SERVER = 'imap.qq.com'
EMAIL_ADDRESS = '8785@qq.com'
AUTH_CODE = 'nnfiiimdejf'
FETCH_COUNT = 200
SUBJECT_KEYWORD = '合集转寄'
AUTO_DELETE = True # <--- 是否允许自动删除 (True: 自动删除, False: 需手工确认)
# ============================================
console = Console()
# ================= 预编译正则表达式 (提升性能) =================
RE_COLOR = re.compile(r'\x1b?\[[0-9;]*[A-Za-z]')
RE_DIVIDER = re.compile(r'☆[─]+☆')
RE_WHITESPACE = re.compile(r'\s+')
RE_BBS_HEADER = re.compile(r'^(转寄人|标\s*题|发信站|来\s*源|Date|From|To):', re.IGNORECASE)
# ================= 核心工具函数 =================
def decode_str(s):
"""安全解码邮件头部文本"""
if not s: return "无标题"
parts = decode_header(s)
decoded = []
for value, charset in parts:
if isinstance(value, bytes):
try:
decoded.append(value.decode(charset or 'utf-8', errors='ignore'))
except Exception:
decoded.append(value.decode('gb18030', errors='ignore'))
else:
decoded.append(str(value))
return "".join(decoded).replace('\n', '').replace('\r', '')
def get_email_body(msg):
"""提取邮件的纯文本正文"""
body = ""
if msg.is_multipart():
for part in msg.walk():
if part.get_content_type() == 'text/plain':
charset = part.get_content_charset() or 'utf-8'
try:
payload = part.get_payload(decode=True)
if payload:
body += payload.decode(charset, errors='ignore')
except Exception:
pass
else:
charset = msg.get_content_charset() or 'utf-8'
try:
payload = msg.get_payload(decode=True)
if payload:
body = payload.decode(charset, errors='ignore')
except Exception:
pass
return body
def extract_core_content(text):
"""精准提取第一个发帖内容,剔除多余回复和颜色代码"""
if not text: return ""
clean_text = RE_COLOR.sub('', text)
keyword = "的大作中提到:"
if keyword in clean_text:
content_after = clean_text.split(keyword, 1)[1]
first_post = RE_DIVIDER.split(content_after, maxsplit=1)[0]
return RE_WHITESPACE.sub(' ', first_post).strip()
# 备用处理逻辑
core_lines = [
line.strip() for line in clean_text.split('\n')
if not RE_BBS_HEADER.match(line)
]
return RE_WHITESPACE.sub(' ', '\n'.join(core_lines)).strip()
def safe_get_timestamp(date_str, internal_date):
"""统一转换为时间戳,彻底消除带时区与不带时区的时间比较崩溃隐患"""
ts = 0
if date_str:
try:
dt = parsedate_to_datetime(date_str)
ts = dt.timestamp()
except Exception:
pass
if not ts and internal_date:
ts = internal_date.timestamp()
return ts
# ================= 业务逻辑函数 =================
def process_emails(client):
"""处理邮件的主要逻辑"""
all_ids = client.search(['ALL'])
recent_ids = all_ids[-FETCH_COUNT:]
actual_check_count = len(recent_ids)
if actual_check_count == 0:
console.print("[bold yellow]收件箱为空,没有找到任何邮件。[/bold yellow]")
return
console.print(f"[info] [步骤 1/2] 正在拉取最近 {actual_check_count} 封邮件的标题进行初步筛查...")
response = client.fetch(recent_ids, ['BODY.PEEK[HEADER]', 'INTERNALDATE'])
subject_groups = {}
matched_count = 0
# 1. 标题初筛
for uid, data in response.items():
msg = email.message_from_bytes(data.get(b'BODY[HEADER]', b''))
subject = decode_str(msg.get("Subject", ""))
if SUBJECT_KEYWORD and SUBJECT_KEYWORD not in subject:
continue
matched_count += 1
ts = safe_get_timestamp(msg.get("Date"), data.get(b'INTERNALDATE'))
subject_groups.setdefault(subject, []).append((uid, ts))
if matched_count == 0:
console.print(f"[bold yellow]未找到标题包含 '{SUBJECT_KEYWORD}' 的邮件。[/bold yellow]")
return
# 2. 正文深度筛查准备
uids_to_fetch_body = [uid for mails in subject_groups.values() if len(mails) > 1 for uid, _ in mails]
body_dict = {}
if uids_to_fetch_body:
console.print(f"[info] [步骤 2/2] 发现 {len(uids_to_fetch_body)} 封同名标题,正在拉取正文深度对比...")
body_response = client.fetch(uids_to_fetch_body, ['BODY.PEEK[]'])
for uid, data in body_response.items():
msg = email.message_from_bytes(data.get(b'BODY[]', b''))
body_dict[uid] = extract_core_content(get_email_body(msg))
# 3. 分组并判定重复
processed_groups = []
for subject, mails in subject_groups.items():
if len(mails) == 1:
processed_groups.append({
'subject': subject, 'keep_uid': mails[0][0], 'keep_ts': mails[0][1], 'deletes': []
})
else:
content_subgroups = {}
for uid, ts in mails:
c_content = body_dict.get(uid, "")
content_subgroups.setdefault(c_content, []).append((uid, ts))
for c_content, sub_mails in content_subgroups.items():
sorted_mails = sorted(sub_mails, key=lambda x: x[1], reverse=True)
processed_groups.append({
'subject': subject,
'keep_uid': sorted_mails[0][0],
'keep_ts': sorted_mails[0][1],
'deletes': sorted_mails[1:]
})
# 4. 排序并渲染UI
processed_groups.sort(key=lambda x: x['keep_ts'], reverse=True)
render_and_execute(client, processed_groups, actual_check_count, matched_count)
def render_and_execute(client, processed_groups, check_count, matched_count):
"""渲染表格并执行删除操作"""
table_title = f"邮件处理清单 (追溯范围: {check_count} 封 | 匹配到: {matched_count} 封)"
if SUBJECT_KEYWORD:
table_title += f" - 过滤词: '{SUBJECT_KEYWORD}'"
table = Table(title=table_title, show_lines=True)
table.add_column("操作", justify="center")
table.add_column("发送时间", style="cyan")
table.add_column("标题", style="white")
table.add_column("UID", style="dim")
uids_to_delete = []
for group in processed_groups:
subject = group['subject']
# 将时间戳格式化回直观的字符串
keep_date_str = datetime.fromtimestamp(group['keep_ts']).strftime('%Y-%m-%d %H:%M') if group['keep_ts'] else "未知时间"
table.add_row(Text("保留", style="bold green"), keep_date_str, subject, str(group['keep_uid']))
for del_uid, del_ts in group['deletes']:
uids_to_delete.append(del_uid)
del_date_str = datetime.fromtimestamp(del_ts).strftime('%Y-%m-%d %H:%M') if del_ts else "未知时间"
table.add_row(Text("删除", style="bold red"), del_date_str, Text(subject, style="dim"), str(del_uid))
console.print(table)
# 5. 执行清理 (根据 AUTO_DELETE 变量决定策略)
if uids_to_delete:
console.print(f"\n[bold yellow]在比对标题与正文首帖后,发现了 {len(uids_to_delete)} 封完全重复的邮件。[/bold yellow]")
if AUTO_DELETE:
console.print("[bold cyan]➜ 已开启自动删除模式,正在清理服务器邮件...[/bold cyan]")
client.delete_messages(uids_to_delete)
client.expunge()
console.print("[bold green]✔ 重复邮件已成功自动彻底删除![/bold green]")
else:
if Confirm.ask("确定要从服务器上彻底删除这些重复邮件吗?(不可逆)"):
client.delete_messages(uids_to_delete)
client.expunge()
console.print("[bold green]✔ 重复邮件已成功彻底删除![/bold green]")
else:
console.print("[info] 操作取消。")
else:
console.print(f"[bold green]检查完毕,没有发现完全重复的邮件。[/bold green]")
# ================= 主程序入口 =================
if __name__ == "__main__":
try:
with IMAPClient(IMAP_SERVER, use_uid=True) as client:
with console.status("[bold green]正在连接并登录QQ邮箱..."):
client.login(EMAIL_ADDRESS, AUTH_CODE)
client.select_folder('INBOX', readonly=False)
process_emails(client)
except KeyboardInterrupt:
console.print("\n[bold red]检测到用户中止操作 (Ctrl+C),程序已安全退出。[/bold red]")
except Exception as e:
console.print(f"\n[bold red]执行过程中发生错误:[/bold red] {e}")
3. 将QQ邮箱内的水木论坛合集邮件发布到我的Halo博客
对合集邮件正文进行html格式处理,并将n天前(防止近期仍有更新)的邮件发布至Halo博客。
注意:只读取发布未读的QQ邮件,已读邮件不会处理,发布到Halo后邮件自动设置为已读状态。
import imaplib
import email
from email.header import decode_header
import email.utils
import requests
import json
import re
import time
import datetime
import html
# ================= 1. 基础配置 =================
QQ_EMAIL = "8785@qq.com"
QQ_AUTH_CODE = "nndejf"
IMAP_SERVER = "imap.qq.com"
HALO_URL = "https://blog.sortiey.com"
HALO_PAT = "pat_eyJraWQiOCI_VyAA5jO2o5v8G8"
# ================= 2. 规则配置 =================
TARGET_KEYWORD = "合集转寄"
MAX_TARGET_EMAILS = 20 # 单次最大处理量
MARK_AS_READ = True # 发布成功后标记为已读
# 【时间规则】不发布最近 N 天内发表的帖子 (填0则不限制时间)
IGNORE_RECENT_DAYS = 1
# ================= 3. 样式与分类配置 =================
MAIN_TEXT_SIZE = "17px"
QUOTE_TEXT_SIZE = "15px"
POST_CATEGORY = "水木论坛"
POST_TAG = "水木论坛"
# ===============================================
# --- 预编译正则表达式 ---
COLOR_REGEX = re.compile(r'(?:\x1B)?\[[0-9;]*[mK]')
DELIMITER_REGEX = re.compile(r'(?:\u2606|☆)[\u2500\u2014\-\s]{5,}(?:\u2606|☆)')
BBCODE_REGEX = re.compile(r'\[/?(?:b|i|u|s|color|size|font|align|url|img|email|quote|code)(?:=[^\]]*)?\]', re.IGNORECASE)
def safe_decode(payload, charset):
if not payload: return ""
charset = charset.lower() if charset else 'utf-8'
if 'gb' in charset or 'unknown' in charset:
charset = 'gb18030'
try:
return payload.decode(charset)
except UnicodeDecodeError:
alt_charset = 'utf-8' if charset == 'gb18030' else 'gb18030'
try:
return payload.decode(alt_charset)
except UnicodeDecodeError:
return payload.decode(charset, 'ignore')
except LookupError:
return payload.decode('utf-8', 'ignore')
def decode_str(s):
if not s: return ""
try:
value, charset = decode_header(s)[0]
if isinstance(value, bytes):
return safe_decode(value, charset)
return value
except Exception:
return str(s)
def extract_email_body(msg):
if msg.is_multipart():
for part in msg.walk():
ctype = part.get_content_type()
cdisp = str(part.get("Content-Disposition"))
if ctype == "text/plain" and "attachment" not in cdisp:
return safe_decode(part.get_payload(decode=True), part.get_content_charset())
else:
return safe_decode(msg.get_payload(decode=True), msg.get_content_charset())
return ""
def parse_sm_content(raw_text):
if not raw_text.strip(): return "", []
clean = re.sub(r'[\x00-\x08\x0b\x0c\x0e-\x1f\x7f]', '', raw_text)
clean = clean.replace('\ufffd', '')
clean = COLOR_REGEX.sub('', clean)
clean = BBCODE_REGEX.sub('', clean)
lines = clean.split('\n')
filtered_lines = []
for line in lines:
if DELIMITER_REGEX.search(line):
filtered_lines.append(line)
continue
trimmed = line.strip()
if not trimmed: continue
f_idx, l_idx = trimmed.find('发自'), trimmed.find('来自')
target_idx = min(f_idx, l_idx) if f_idx != -1 and l_idx != -1 else max(f_idx, l_idx)
if target_idx != -1 and not re.search(r'[\u4e00-\u9fa5]', trimmed[:target_idx]):
continue
if not re.search(r'[A-Za-z0-9\u4e00-\u9fa5]', trimmed):
continue
filtered_lines.append(line)
clean_text = '\n'.join(filtered_lines)
blocks = DELIMITER_REGEX.split(clean_text)
floors = []
header_text = ''
if len(blocks) == 1:
floors = [{'author': '未知', 'nick': '', 'time': '', 'main': clean_text, 'quote': ''}]
else:
header_text = blocks[0].strip()
for i in range(1, len(blocks)):
block = blocks[i].strip()
if not block: continue
author, nick, time_str = '未知', '', ''
meta_match = re.search(r'^([\s\S]*?)的大作中提到[::](?:[\r\n]+([\s\S]*))?$', block)
if meta_match:
head = meta_match.group(1)
content = meta_match.group(2) or ""
u_match = re.search(r'^\s*(.*?)\s*\((.*?)\)', head)
if u_match: author, nick = u_match.group(1).strip(), u_match.group(2).strip()
t_match = re.search(r'于\s*\(?(.*?)\)?\s*在', head)
if t_match: time_str = t_match.group(1).strip()
else:
content = block
q_match = re.search(r'【\s*在\s+[\s\S]*?的大作中提到[::]\s*】', content)
s_match = re.search(r'(--\s*FROM|-+\s*[发来]自|[发来]自「.*?」)', content, re.IGNORECASE)
q_idx = q_match.start() if q_match else -1
s_idx = s_match.start() if s_match else -1
text_without_sig = content[:s_idx].strip() if s_idx != -1 else content
main_text, quote_text = '', ''
if q_idx != -1:
before_quote = text_without_sig[:q_idx].strip()
if before_quote == '':
t_lines = text_without_sig.split('\n')
quote_lines, main_lines = [], []
in_quote, header_passed = True, False
for t_line in t_lines:
if in_quote:
if not header_passed:
quote_lines.append(t_line)
if t_line.strip().endswith('】'): header_passed = True
elif t_line.strip().startswith(':') or t_line.strip().startswith(':') or t_line.strip() == '':
quote_lines.append(t_line)
else:
in_quote = False
main_lines.append(t_line)
else:
main_lines.append(t_line)
while quote_lines and quote_lines[-1].strip() == '': quote_lines.pop()
quote_text, main_text = '\n'.join(quote_lines).strip(), '\n'.join(main_lines).strip()
else:
main_text, quote_text = text_without_sig[:q_idx].strip(), text_without_sig[q_idx:].strip()
else:
main_text = text_without_sig.strip()
main_text = re.sub(r'\n{3,}', '\n\n', main_text)
floors.append({'author': author, 'nick': nick, 'time': time_str, 'main': main_text, 'quote': quote_text})
return header_text, floors
def render_sm_html(header_text, floors):
unique_id = f"sm_{int(time.time()*1000)}"
system_font = '\"Inter\", -apple-system, BlinkMacSystemFont, \"Segoe UI\", Roboto, \"Helvetica Neue\", Arial, sans-serif'
mono_font = '\"Fira Code\", \"SFMono-Regular\", Consolas, \"Liberation Mono\", Menlo, Courier, monospace'
html_out = f"""
<div id="{unique_id}" class="sm-export-container dark-mode">
<style>
#{unique_id}, #{unique_id} * {{ -webkit-font-smoothing: antialiased !important; -moz-osx-font-smoothing: grayscale !important; text-shadow: none !important; -webkit-text-stroke: 0 !important; }}
#{unique_id} {{ --bg: #121212; --card: #262626; --text: #e2e8f0; --sec: #94a3b8; --ter: #64748b; --border: #333333; --quote: rgba(0,0,0,0.2); --q-border: #3b82f6; --h-bg: rgba(0,0,0,0.3); font-family: {system_font} !important; padding: 20px 6px !important; transition: all 0.3s ease !important; background: var(--bg) !important; color: var(--text) !important; box-sizing: border-box !important; width: 100% !important; border-radius: 8px !important; }}
#{unique_id}.light-mode {{ --bg: #f3f4f6; --card: #ffffff; --text: #111827; --sec: #4b5563; --ter: #9ca3af; --border: #e5e7eb; --quote: #f3f4f6; --q-border: #a3b8cc; --h-bg: #f9fafb; }}
#{unique_id} .export-btn {{ margin-bottom: 16px !important; padding: 6px 14px !important; cursor: pointer !important; border-radius: 20px !important; border: 1px solid var(--border) !important; background: var(--card) !important; color: var(--text) !important; font-size: 13px !important; font-weight: 500 !important; transition: all 0.2s !important;}}
#{unique_id} .export-btn:hover {{ border-color: var(--ter) !important; }}
#{unique_id} .thread-header {{ font-family: {mono_font} !important; font-size: 12px !important; color: var(--ter) !important; margin-bottom: 16px !important; padding: 10px 14px !important; background: var(--h-bg) !important; border-radius: 8px !important; border: 1px solid var(--border) !important; line-height: 1.6 !important; }}
#{unique_id} .floor-card {{ background: var(--card) !important; border: 1px solid var(--border) !important; border-radius: 8px !important; padding: 10px 4px !important; margin-bottom: 16px !important; text-align: left !important; }}
#{unique_id} .floor-meta {{ display: flex !important; justify-content: space-between !important; margin-bottom: 8px !important; padding-bottom: 8px !important; border-bottom: 1px solid var(--border) !important; }}
#{unique_id} .floor-meta-left strong {{ color: var(--text) !important; font-size: 15px !important; font-family: {system_font} !important; font-weight: 600 !important; }}
#{unique_id} .floor-meta-left span {{ color: var(--sec) !important; font-size: 13px !important; margin-left: 8px !important; font-family: {system_font} !important; font-weight: normal !important; }}
#{unique_id} .floor-meta-right {{ color: var(--ter) !important; font-family: {mono_font} !important; font-size: 12px !important; font-weight: normal !important; }}
#{unique_id} .floor-body {{ font-size: {MAIN_TEXT_SIZE} !important; color: var(--text) !important; font-family: {system_font} !important; font-weight: normal !important; line-height: 1.8 !important; white-space: pre-wrap !important; word-break: break-word !important; letter-spacing: normal !important; margin: 0 !important; padding: 0 !important; }}
#{unique_id} .floor-quote {{ margin-top: 10px !important; padding: 10px 14px !important; background: var(--quote) !important; border-left: 4px solid var(--q-border) !important; border-radius: 4px !important; font-family: {system_font} !important; font-size: {QUOTE_TEXT_SIZE} !important; color: var(--sec) !important; white-space: pre-wrap !important; line-height: 1.7 !important; font-weight: normal !important; }}
</style>
<button class="export-btn" onclick="document.getElementById('{unique_id}').classList.toggle('light-mode')">🌓 切换明暗主题</button>
"""
if header_text:
html_out += f' <div class="thread-header">{html.escape(header_text).replace(chr(10), "<br>")}</div>\n'
for idx, f in enumerate(floors):
html_out += f""" <div class="floor-card">
<div class="floor-meta">
<div class="floor-meta-left"><strong>{html.escape(f['author'])}</strong><span>{html.escape(f['nick'])}</span></div>
<div class="floor-meta-right">{html.escape(f['time'])} · #{idx+1}</div>
</div>
<div class="floor-body">{html.escape(f['main'])}</div>"""
if f['quote']: html_out += f'\n <div class="floor-quote">{html.escape(f["quote"])}</div>'
html_out += "\n </div>\n"
html_out += "</div>"
return html_out
def get_halo_metadata_name(session, resource_type, display_name):
api_url = f"{HALO_URL}/apis/content.halo.run/v1alpha1/{resource_type}?size=100"
try:
resp = session.get(api_url)
if resp.status_code == 200:
for item in resp.json().get("items", []):
if item.get("spec", {}).get("displayName") == display_name:
return item.get("metadata", {}).get("name")
except Exception:
pass
return None
def get_iso_time(sm_time_str, email_date_str):
dt = None
if sm_time_str:
sm_time_str = sm_time_str.strip()
try:
dt = datetime.datetime.strptime(sm_time_str, "%Y-%m-%d %H:%M:%S")
except ValueError:
pass
if not dt:
try:
clean_time = " ".join(sm_time_str.split())
month_map = {"Jan": 1, "Feb": 2, "Mar": 3, "Apr": 4, "May": 5, "Jun": 6,
"Jul": 7, "Aug": 8, "Sep": 9, "Oct": 10, "Nov": 11, "Dec": 12}
m = re.search(r'[A-Za-z]{3}\s+([A-Za-z]{3})\s+(\d+)\s+(\d+):(\d+):(\d+)\s+(\d+)', clean_time)
if m:
mon_str, day, H, M, S, year = m.groups()
mon = month_map.get(mon_str, 1)
dt = datetime.datetime(int(year), mon, int(day), int(H), int(M), int(S))
except Exception:
pass
if dt:
tz = datetime.timezone(datetime.timedelta(hours=8))
dt = dt.replace(tzinfo=tz)
return dt.isoformat(timespec='seconds')
if email_date_str:
try:
dt = email.utils.parsedate_to_datetime(email_date_str)
if dt.tzinfo is None:
dt = dt.replace(tzinfo=datetime.timezone.utc)
return dt.isoformat(timespec='seconds')
except Exception:
pass
return datetime.datetime.now(datetime.timezone.utc).isoformat(timespec='seconds')
def post_to_halo(session, eid, title, html_content, category_id, tag_id, publish_time_iso):
api_url = f"{HALO_URL}/apis/api.console.halo.run/v1alpha1/posts"
unique_slug = f"sm-{eid}-{int(time.time() * 1000)}"
clean_title = re.sub(r'[\r\n\t]+', ' ', title).strip()
payload = {
"post": {
"apiVersion": "content.halo.run/v1alpha1",
"kind": "Post",
"metadata": {"generateName": "sm-post-"},
"spec": {
"title": clean_title,
"slug": unique_slug,
"publish": True,
"publishTime": publish_time_iso,
"allowComment": True,
"visible": "PUBLIC",
"pinned": False,
"priority": 0,
"deleted": False,
"excerpt": {"autoGenerate": True, "raw": ""}
}
},
"content": {
"raw": html_content,
"content": html_content,
"rawType": "html"
}
}
if category_id: payload["post"]["spec"]["categories"] = [category_id]
if tag_id: payload["post"]["spec"]["tags"] = [tag_id]
response = session.post(api_url, json=payload)
if response.status_code in [200, 201]:
print(f"✅ 成功发布: {clean_title} [时间: {publish_time_iso}]")
return True
else:
print(f"❌ 发布失败 ({response.status_code}): {response.text}")
return False
def fetch_and_process():
api_session = requests.Session()
api_session.headers.update({
"Authorization": f"Bearer {HALO_PAT}"
})
mail = None
try:
print(">> 步骤1: 获取 Halo 博客基建数据...")
category_id = get_halo_metadata_name(api_session, "categories", POST_CATEGORY)
tag_id = get_halo_metadata_name(api_session, "tags", POST_TAG)
print(">> 步骤2: 连接 QQ 邮箱服务器...")
mail = imaplib.IMAP4_SSL(IMAP_SERVER, 993)
mail.login(QQ_EMAIL, QQ_AUTH_CODE)
mail.select("INBOX")
print(">> 正在向服务器发送关键字查询指令...")
# 【服务端极速过滤】:使用 utf-8 编码精确搜索
status, messages = mail.search('UTF-8', 'UNSEEN', 'SUBJECT', TARGET_KEYWORD.encode('utf-8'))
if status != "OK" or not messages[0]:
print("📭 没有找到包含目标关键字的未读邮件。")
return
email_ids = messages[0].split()
print(f" (服务器过滤完成,共找到 {len(email_ids)} 封待检邮件)")
email_ids.reverse()
processed_count = 0
print(f">> 步骤3: 开始处理匹配邮件 (目标最多 {MAX_TARGET_EMAILS} 封)...")
for eid in email_ids:
if processed_count >= MAX_TARGET_EMAILS:
print(f"🛑 已达到最大处理数量 ({MAX_TARGET_EMAILS}),本轮任务结束。")
break
try:
res, header_data = mail.fetch(eid, '(BODY.PEEK[HEADER.FIELDS (SUBJECT DATE)])')
subject_str = ""
email_date_str = ""
for response_part in header_data:
if isinstance(response_part, tuple):
msg_header = email.message_from_bytes(response_part[1])
subject_str = decode_str(msg_header["Subject"])
email_date_str = msg_header.get("Date", "")
break
if TARGET_KEYWORD not in subject_str:
continue
print(f"📬 正在下载目标邮件内容: {subject_str.strip()}")
res, msg_data = mail.fetch(eid, '(RFC822)')
msg = None
for response_part in msg_data:
if isinstance(response_part, tuple):
msg = email.message_from_bytes(response_part[1])
break
if not msg: continue
raw_body = extract_email_body(msg)
header, floors = parse_sm_content(raw_body)
formatted_html = render_sm_html(header, floors)
if formatted_html:
last_floor_time = floors[-1]['time'] if floors else ""
publish_time_iso = get_iso_time(last_floor_time, email_date_str)
if IGNORE_RECENT_DAYS > 0:
try:
dt_publish = datetime.datetime.fromisoformat(publish_time_iso)
now_dt = datetime.datetime.now(datetime.timezone.utc)
age_days = (now_dt - dt_publish).days
if age_days < IGNORE_RECENT_DAYS:
print(f"⏳ 暂不发布: {subject_str.strip()} (原帖最新回复于 {age_days} 天前,未满 {IGNORE_RECENT_DAYS} 天)")
continue
except Exception:
pass
processed_count += 1
success = post_to_halo(
session=api_session,
eid=eid.decode('utf-8'),
title=subject_str,
html_content=formatted_html,
category_id=category_id,
tag_id=tag_id,
publish_time_iso=publish_time_iso
)
if success and MARK_AS_READ:
mail.store(eid, '+FLAGS', '\\Seen')
except Exception as item_error:
print(f"⚠️ 处理当前邮件时发生异常,已跳过 ({item_error})")
continue
print(f"🎉 运行完毕,本次共发布了 {processed_count} 篇文章。")
except Exception as e:
print(f"❌ 发生网络或系统错误: {e}")
finally:
if mail:
try:
mail.logout()
print("🔌 邮箱连接已安全断开。")
except:
pass
api_session.close()
if __name__ == "__main__":
fetch_and_process()
4. 将QQ邮箱内的同一主题不同的水木论坛合集邮件合并发布到我的Halo博客
由于邮件合集中同一主题如果第一个帖子内容不一样则都保留,导致同一主题邮件可能存在多个。本程序对这些同主题的多封合集转寄邮件按照每个帖子的发帖先后时间顺序进行合并,并在处理后发布到Halo。
注意:会将QQ邮箱内已读和未读的同主题邮件合并,合并后这些邮件都会设置为已读邮件。
# ===== 将QQ邮箱内标题相同的水木合集邮件组按照发帖时间进行合并去重,并发布到Halo博客 =====
import imaplib
import email
from email.header import decode_header
import email.utils
import requests
import json
import re
import time
import datetime
import html
from collections import defaultdict
# ================= 1. 基础配置 =================
QQ_EMAIL = "8785@qq.com"
QQ_AUTH_CODE = "nnfiemdejf" # QQ邮箱授权码 设置-账号与安全-安全设置-生成授权码
IMAP_SERVER = "imap.qq.com"
HALO_URL = "https://blog.sortie.com"
HALO_PAT = "pat_eyJraWQiOiJr0ku5jO2o5v8G8"
# ================= 2. 规则配置 =================
TARGET_KEYWORD = "合集转寄"
MAX_TARGET_EMAILS = 50 # 单次最大处理量(这里指处理多少个不重复的标题组)
MARK_AS_READ = True # 发布成功后标记为已读
# 【新增控制开关】是否仅处理包含多封邮件的重复标题?
# 设为 True 时,单封非重复标题的邮件将被跳过;设为 False 则所有包含关键字的邮件都将被处理、内部去重并发布。
ONLY_PROCESS_DUPLICATES = True
# 【时间规则】不发布最近 N 天内发表的帖子 (填0则不限制时间)
IGNORE_RECENT_DAYS = 4
# ================= 3. 样式与分类配置 =================
MAIN_TEXT_SIZE = "17px"
QUOTE_TEXT_SIZE = "15px"
POST_CATEGORY = "水木论坛"
POST_TAG = "水木论坛"
# ===============================================
# --- 预编译正则表达式 ---
COLOR_REGEX = re.compile(r'(?:\x1B)?\[[0-9;]*[mK]')
DELIMITER_REGEX = re.compile(r'(?:\u2606|☆)[\u2500\u2014\-\s]{5,}(?:\u2606|☆)')
BBCODE_REGEX = re.compile(r'\[/?(?:b|i|u|s|color|size|font|align|url|img|email|quote|code)(?:=[^\]]*)?\]', re.IGNORECASE)
def safe_decode(payload, charset):
if not payload: return ""
charset = charset.lower() if charset else 'utf-8'
if 'gb' in charset or 'unknown' in charset:
charset = 'gb18030'
try:
return payload.decode(charset)
except UnicodeDecodeError:
alt_charset = 'utf-8' if charset == 'gb18030' else 'gb18030'
try:
return payload.decode(alt_charset)
except UnicodeDecodeError:
return payload.decode(charset, 'ignore')
except LookupError:
return payload.decode('utf-8', 'ignore')
def decode_str(s):
if not s: return ""
try:
value, charset = decode_header(s)[0]
if isinstance(value, bytes):
return safe_decode(value, charset)
return value
except Exception:
return str(s)
def extract_email_body(msg):
if msg.is_multipart():
for part in msg.walk():
ctype = part.get_content_type()
cdisp = str(part.get("Content-Disposition"))
if ctype == "text/plain" and "attachment" not in cdisp:
return safe_decode(part.get_payload(decode=True), part.get_content_charset())
else:
return safe_decode(msg.get_payload(decode=True), msg.get_content_charset())
return ""
def parse_sm_content(raw_text):
if not raw_text.strip(): return "", []
clean = re.sub(r'[\x00-\x08\x0b\x0c\x0e-\x1f\x7f]', '', raw_text)
clean = clean.replace('\ufffd', '')
clean = COLOR_REGEX.sub('', clean)
clean = BBCODE_REGEX.sub('', clean)
lines = clean.split('\n')
filtered_lines = []
for line in lines:
if DELIMITER_REGEX.search(line):
filtered_lines.append(line)
continue
trimmed = line.strip()
if not trimmed: continue
f_idx, l_idx = trimmed.find('发自'), trimmed.find('来自')
target_idx = min(f_idx, l_idx) if f_idx != -1 and l_idx != -1 else max(f_idx, l_idx)
if target_idx != -1 and not re.search(r'[\u4e00-\u9fa5]', trimmed[:target_idx]):
continue
if not re.search(r'[A-Za-z0-9\u4e00-\u9fa5]', trimmed):
continue
filtered_lines.append(line)
clean_text = '\n'.join(filtered_lines)
blocks = DELIMITER_REGEX.split(clean_text)
floors = []
header_text = ''
if len(blocks) == 1:
floors = [{'author': '未知', 'nick': '', 'time': '', 'main': clean_text, 'quote': ''}]
else:
header_text = blocks[0].strip()
for i in range(1, len(blocks)):
block = blocks[i].strip()
if not block: continue
author, nick, time_str = '未知', '', ''
meta_match = re.search(r'^([\s\S]*?)的大作中提到[::](?:[\r\n]+([\s\S]*))?$', block)
if meta_match:
head = meta_match.group(1)
content = meta_match.group(2) or ""
u_match = re.search(r'^\s*(.*?)\s*\((.*?)\)', head)
if u_match: author, nick = u_match.group(1).strip(), u_match.group(2).strip()
t_match = re.search(r'于\s*\(?(.*?)\)?\s*在', head)
if t_match: time_str = t_match.group(1).strip()
else:
content = block
q_match = re.search(r'【\s*在\s+[\s\S]*?的大作中提到[::]\s*】', content)
s_match = re.search(r'(--\s*FROM|-+\s*[发来]自|[发来]自「.*?」)', content, re.IGNORECASE)
q_idx = q_match.start() if q_match else -1
s_idx = s_match.start() if s_match else -1
text_without_sig = content[:s_idx].strip() if s_idx != -1 else content
main_text, quote_text = '', ''
if q_idx != -1:
before_quote = text_without_sig[:q_idx].strip()
if before_quote == '':
t_lines = text_without_sig.split('\n')
quote_lines, main_lines = [], []
in_quote, header_passed = True, False
for t_line in t_lines:
if in_quote:
if not header_passed:
quote_lines.append(t_line)
if t_line.strip().endswith('】'): header_passed = True
elif t_line.strip().startswith(':') or t_line.strip().startswith(':') or t_line.strip() == '':
quote_lines.append(t_line)
else:
in_quote = False
main_lines.append(t_line)
else:
main_lines.append(t_line)
while quote_lines and quote_lines[-1].strip() == '': quote_lines.pop()
quote_text, main_text = '\n'.join(quote_lines).strip(), '\n'.join(main_lines).strip()
else:
main_text, quote_text = text_without_sig[:q_idx].strip(), text_without_sig[q_idx:].strip()
else:
main_text = text_without_sig.strip()
main_text = re.sub(r'\n{3,}', '\n\n', main_text)
floors.append({'author': author, 'nick': nick, 'time': time_str, 'main': main_text, 'quote': quote_text})
return header_text, floors
def render_sm_html(header_text, floors):
unique_id = f"sm_{int(time.time()*1000)}"
system_font = '\"Inter\", -apple-system, BlinkMacSystemFont, \"Segoe UI\", Roboto, \"Helvetica Neue\", Arial, sans-serif'
mono_font = '\"Fira Code\", \"SFMono-Regular\", Consolas, \"Liberation Mono\", Menlo, Courier, monospace'
html_out = f"""
<div id="{unique_id}" class="sm-export-container dark-mode">
<style>
#{unique_id}, #{unique_id} * {{ -webkit-font-smoothing: antialiased !important; -moz-osx-font-smoothing: grayscale !important; text-shadow: none !important; -webkit-text-stroke: 0 !important; }}
#{unique_id} {{ --bg: #121212; --card: #262626; --text: #e2e8f0; --sec: #94a3b8; --ter: #64748b; --border: #333333; --quote: rgba(0,0,0,0.2); --q-border: #3b82f6; --h-bg: rgba(0,0,0,0.3); font-family: {system_font} !important; padding: 20px 6px !important; transition: all 0.3s ease !important; background: var(--bg) !important; color: var(--text) !important; box-sizing: border-box !important; width: 100% !important; border-radius: 8px !important; }}
#{unique_id}.light-mode {{ --bg: #f3f4f6; --card: #ffffff; --text: #111827; --sec: #4b5563; --ter: #9ca3af; --border: #e5e7eb; --quote: #f3f4f6; --q-border: #a3b8cc; --h-bg: #f9fafb; }}
#{unique_id} .export-btn {{ margin-bottom: 16px !important; padding: 6px 14px !important; cursor: pointer !important; border-radius: 20px !important; border: 1px solid var(--border) !important; background: var(--card) !important; color: var(--text) !important; font-size: 13px !important; font-weight: 500 !important; transition: all 0.2s !important;}}
#{unique_id} .export-btn:hover {{ border-color: var(--ter) !important; }}
#{unique_id} .thread-header {{ font-family: {mono_font} !important; font-size: 12px !important; color: var(--ter) !important; margin-bottom: 16px !important; padding: 10px 14px !important; background: var(--h-bg) !important; border-radius: 8px !important; border: 1px solid var(--border) !important; line-height: 1.6 !important; }}
#{unique_id} .floor-card {{ background: var(--card) !important; border: 1px solid var(--border) !important; border-radius: 8px !important; padding: 10px 4px !important; margin-bottom: 16px !important; text-align: left !important; }}
#{unique_id} .floor-meta {{ display: flex !important; justify-content: space-between !important; margin-bottom: 8px !important; padding-bottom: 8px !important; border-bottom: 1px solid var(--border) !important; }}
#{unique_id} .floor-meta-left strong {{ color: var(--text) !important; font-size: 15px !important; font-family: {system_font} !important; font-weight: 600 !important; }}
#{unique_id} .floor-meta-left span {{ color: var(--sec) !important; font-size: 13px !important; margin-left: 8px !important; font-family: {system_font} !important; font-weight: normal !important; }}
#{unique_id} .floor-meta-right {{ color: var(--ter) !important; font-family: {mono_font} !important; font-size: 12px !important; font-weight: normal !important; }}
#{unique_id} .floor-body {{ font-size: {MAIN_TEXT_SIZE} !important; color: var(--text) !important; font-family: {system_font} !important; font-weight: normal !important; line-height: 1.8 !important; white-space: pre-wrap !important; word-break: break-word !important; letter-spacing: normal !important; margin: 0 !important; padding: 0 !important; }}
#{unique_id} .floor-quote {{ margin-top: 10px !important; padding: 10px 14px !important; background: var(--quote) !important; border-left: 4px solid var(--q-border) !important; border-radius: 4px !important; font-family: {system_font} !important; font-size: {QUOTE_TEXT_SIZE} !important; color: var(--sec) !important; white-space: pre-wrap !important; line-height: 1.7 !important; font-weight: normal !important; }}
</style>
<button class="export-btn" onclick="document.getElementById('{unique_id}').classList.toggle('light-mode')">🌓 切换明暗主题</button>
"""
if header_text:
html_out += f' <div class="thread-header">{html.escape(header_text).replace(chr(10), "<br>")}</div>\n'
for idx, f in enumerate(floors):
html_out += f""" <div class="floor-card">
<div class="floor-meta">
<div class="floor-meta-left"><strong>{html.escape(f['author'])}</strong><span>{html.escape(f['nick'])}</span></div>
<div class="floor-meta-right">{html.escape(f['time'])} · #{idx+1}</div>
</div>
<div class="floor-body">{html.escape(f['main'])}</div>"""
if f['quote']: html_out += f'\n <div class="floor-quote">{html.escape(f["quote"])}</div>'
html_out += "\n </div>\n"
html_out += "</div>"
return html_out
def get_halo_metadata_name(session, resource_type, display_name):
api_url = f"{HALO_URL}/apis/content.halo.run/v1alpha1/{resource_type}?size=100"
try:
resp = session.get(api_url)
if resp.status_code == 200:
for item in resp.json().get("items", []):
if item.get("spec", {}).get("displayName") == display_name:
return item.get("metadata", {}).get("name")
except Exception:
pass
return None
def get_iso_time(sm_time_str, email_date_str):
dt = None
if sm_time_str:
sm_time_str = sm_time_str.strip()
try:
dt = datetime.datetime.strptime(sm_time_str, "%Y-%m-%d %H:%M:%S")
except ValueError:
pass
if not dt:
try:
clean_time = " ".join(sm_time_str.split())
month_map = {"Jan": 1, "Feb": 2, "Mar": 3, "Apr": 4, "May": 5, "Jun": 6,
"Jul": 7, "Aug": 8, "Sep": 9, "Oct": 10, "Nov": 11, "Dec": 12}
m = re.search(r'[A-Za-z]{3}\s+([A-Za-z]{3})\s+(\d+)\s+(\d+):(\d+):(\d+)\s+(\d+)', clean_time)
if m:
mon_str, day, H, M, S, year = m.groups()
mon = month_map.get(mon_str, 1)
dt = datetime.datetime(int(year), mon, int(day), int(H), int(M), int(S))
except Exception:
pass
if dt:
tz = datetime.timezone(datetime.timedelta(hours=8))
dt = dt.replace(tzinfo=tz)
return dt.isoformat(timespec='seconds')
if email_date_str:
try:
dt = email.utils.parsedate_to_datetime(email_date_str)
if dt.tzinfo is None:
dt = dt.replace(tzinfo=datetime.timezone.utc)
return dt.isoformat(timespec='seconds')
except Exception:
pass
return datetime.datetime.now(datetime.timezone.utc).isoformat(timespec='seconds')
def post_to_halo(session, eid, title, html_content, category_id, tag_id, publish_time_iso):
api_url = f"{HALO_URL}/apis/api.console.halo.run/v1alpha1/posts"
unique_slug = f"sm-{eid}-{int(time.time() * 1000)}"
clean_title = re.sub(r'[\r\n\t]+', ' ', title).strip()
payload = {
"post": {
"apiVersion": "content.halo.run/v1alpha1",
"kind": "Post",
"metadata": {"generateName": "sm-post-"},
"spec": {
"title": clean_title,
"slug": unique_slug,
"publish": True,
"publishTime": publish_time_iso,
"allowComment": True,
"visible": "PUBLIC",
"pinned": False,
"priority": 0,
"deleted": False,
"excerpt": {"autoGenerate": True, "raw": ""}
}
},
"content": {
"raw": html_content,
"content": html_content,
"rawType": "html"
}
}
if category_id: payload["post"]["spec"]["categories"] = [category_id]
if tag_id: payload["post"]["spec"]["tags"] = [tag_id]
response = session.post(api_url, json=payload)
if response.status_code in [200, 201]:
print(f"✅ 成功发布: {clean_title} [最新时间: {publish_time_iso}]")
return True
else:
print(f"❌ 发布失败 ({response.status_code}): {response.text}")
return False
def fetch_and_process():
api_session = requests.Session()
api_session.headers.update({
"Authorization": f"Bearer {HALO_PAT}"
})
mail = None
try:
print(">> 步骤1: 获取 Halo 博客基建数据...")
category_id = get_halo_metadata_name(api_session, "categories", POST_CATEGORY)
tag_id = get_halo_metadata_name(api_session, "tags", POST_TAG)
print(">> 步骤2: 连接 QQ 邮箱服务器...")
mail = imaplib.IMAP4_SSL(IMAP_SERVER, 993)
mail.login(QQ_EMAIL, QQ_AUTH_CODE)
mail.select("INBOX")
print(">> 正在向服务器发送关键字查询指令...")
# 【修改1】使用 ALL 参数查询包含目标关键字的所有邮件(包括已读和未读)
status, messages = mail.search('UTF-8', 'ALL', 'SUBJECT', TARGET_KEYWORD.encode('utf-8'))
if status != "OK" or not messages[0]:
print("📭 没有找到包含目标关键字的邮件。")
return
email_ids = messages[0].split()
print(f" (服务器过滤完成,共找到 {len(email_ids)} 封待检邮件)")
# 倒序,优先处理新邮件
email_ids.reverse()
# 【修改2】提取标题进行分组聚合
print(">> 步骤3: 获取邮件头并按重复标题进行分组...")
subject_groups = defaultdict(list)
email_dates = {}
for eid in email_ids:
res, header_data = mail.fetch(eid, '(BODY.PEEK[HEADER.FIELDS (SUBJECT DATE)])')
subject_str = ""
email_date_str = ""
for response_part in header_data:
if isinstance(response_part, tuple):
msg_header = email.message_from_bytes(response_part[1])
subject_str = decode_str(msg_header["Subject"]).strip()
email_date_str = msg_header.get("Date", "")
break
# 过滤包含目标关键字的有效邮件进行分组
if TARGET_KEYWORD in subject_str:
subject_groups[subject_str].append(eid)
email_dates[eid] = email_date_str
print(f" (分组完成,共 {len(subject_groups)} 个独立的主题聚合组)")
processed_count = 0
print(f">> 步骤4: 开始合并并处理邮件内容 (目标最多处理 {MAX_TARGET_EMAILS} 组)...")
for subject, group_eids in subject_groups.items():
if processed_count >= MAX_TARGET_EMAILS:
print(f"🛑 已达到最大处理数量 ({MAX_TARGET_EMAILS}),本轮任务结束。")
break
# 如果用户设定仅处理有重复标题(即聚合后数量 >= 2)的邮件
if ONLY_PROCESS_DUPLICATES and len(group_eids) < 2:
continue
print(f"📬 正在处理聚合组: {subject} (组内包含 {len(group_eids)} 封邮件)")
all_floors = []
seen_signatures = set()
merged_header_text = ""
# 【修改3】读取组内所有重复邮件正文
for eid in group_eids:
res, msg_data = mail.fetch(eid, '(RFC822)')
msg = None
for response_part in msg_data:
if isinstance(response_part, tuple):
msg = email.message_from_bytes(response_part[1])
break
if not msg: continue
raw_body = extract_email_body(msg)
header, floors = parse_sm_content(raw_body)
# 提取第一封有头部的邮件作为统一的顶部 header
if header and not merged_header_text:
merged_header_text = header
email_date_str = email_dates.get(eid, "")
# 【修改4】合并并去重
for f in floors:
author = f.get('author', '').strip()
time_str = f.get('time', '').strip()
main_content = f.get('main', '').strip()
# 按照 发帖人+发布时间+内容 组成唯一指纹进行去重
sig = (author, time_str, main_content)
if sig not in seen_signatures:
seen_signatures.add(sig)
# 转换出一个标准的 ISO 8601 字符串用于后续的绝对时间排序
sort_time = get_iso_time(time_str, email_date_str)
f['sort_key'] = sort_time
all_floors.append(f)
if not all_floors:
continue
# 【修改5】将所有收集到的不重复帖子,按照时间先后顺序排序
all_floors.sort(key=lambda x: x['sort_key'])
# 生成 HTML(传入合并后的 Header 以及去重排序后的全量 Floors)
formatted_html = render_sm_html(merged_header_text, all_floors)
if formatted_html:
# 提取原帖最新一次回复的时间,用于决定发布时间和最近天数屏蔽逻辑
last_floor_time = all_floors[-1]['sort_key']
if IGNORE_RECENT_DAYS > 0:
try:
dt_publish = datetime.datetime.fromisoformat(last_floor_time)
now_dt = datetime.datetime.now(datetime.timezone.utc)
age_days = (now_dt - dt_publish).days
if age_days < IGNORE_RECENT_DAYS:
print(f"⏳ 暂不发布: {subject} (原帖最新回复于 {age_days} 天前,未满 {IGNORE_RECENT_DAYS} 天)")
continue
except Exception:
pass
processed_count += 1
# 发布到 Halo 博客,使用此聚合组中第一封邮件的 ID 生成唯一 Slug
success = post_to_halo(
session=api_session,
eid=group_eids[0].decode('utf-8'),
title=subject,
html_content=formatted_html,
category_id=category_id,
tag_id=tag_id,
publish_time_iso=last_floor_time
)
# 如果发布成功,将该聚合组内参与合并的【所有】邮件全标记为已读
if success and MARK_AS_READ:
for eid in group_eids:
mail.store(eid, '+FLAGS', '\\Seen')
print(f"🎉 运行完毕,本次共发布了 {processed_count} 篇合集文章。")
except Exception as e:
print(f"❌ 发生网络或系统错误: {e}")
finally:
if mail:
try:
mail.logout()
print("🔌 邮箱连接已安全断开。")
except:
pass
api_session.close()
if __name__ == "__main__":
fetch_and_process()
5. 清除Halo中重复发布的水木论坛合集帖子
# ====== 删除Halo博客中重复的水木合集,只保留最新创建的文章,文章发布时间仍与帖子最后回复时间保持一致 =======
import requests
from collections import defaultdict
# ================= 配置信息 =================
HALO_URL = "https://blog.sortie.com"
HALO_PAT = "pat_eyJrAChj-z7gYaVyAA5jO2o5v8G8"
# 诊断关键词
DEBUG_KEYWORD = "合集转寄"
# ============================================
def clean_duplicate_posts():
api_session = requests.Session()
api_session.headers.update({"Authorization": f"Bearer {HALO_PAT}"})
print(">> 正在拉取博客底层文章数据...\n")
posts = []
page = 1
while True:
api_url = f"{HALO_URL}/apis/content.halo.run/v1alpha1/posts?page={page}&size=100"
resp = api_session.get(api_url)
if resp.status_code != 200:
print(f"❌ 请求失败 ({resp.status_code}): {resp.text}")
return
data = resp.json()
items = data.get("items", [])
if not items:
break
posts.extend(items)
if not data.get("hasNext", False) and len(items) < 100:
break
page += 1
# ====== 新增:显示总拉取文章数 ======
print(f">> ✅ 数据拉取完毕!底层接口共返回了 {len(posts)} 篇文章。\n")
title_map = defaultdict(list)
for post in posts:
spec = post.get("spec", {})
title = spec.get("title", "")
# 只筛选包含目标关键词的文章
if DEBUG_KEYWORD in title:
metadata = post.get("metadata", {})
title_map[title].append({
"name": metadata.get("name", ""), # 删除所需的资源标识名
"creation_time": metadata.get("creationTimestamp", ""),
"slug": spec.get("slug", "")
})
duplicate_count = 0
deleted_count = 0
print("-" * 75)
for title, items in title_map.items():
if len(items) > 1:
duplicate_count += 1
print(f"📦 处理重复标题: {repr(title)} (共 {len(items)} 篇)")
# 降序排列,保证索引 0 是最新创建的
sorted_items = sorted(items, key=lambda x: x["creation_time"], reverse=True)
for idx, item in enumerate(sorted_items):
post_name = item['name']
if idx == 0:
print(f" ✅ [保留] 创建时间: {item['creation_time']} | 链接: /archives/{item['slug']}")
else:
print(f" 🗑️ [正在删除] 创建时间: {item['creation_time']} | 资源: {post_name} ...", end=" ")
# 针对唯一名称发起 DELETE 请求
delete_url = f"{HALO_URL}/apis/content.halo.run/v1alpha1/posts/{post_name}"
del_resp = api_session.delete(delete_url)
if del_resp.status_code in [200, 202, 204]:
print("成功")
deleted_count += 1
else:
print(f"失败 ({del_resp.status_code}: {del_resp.text})")
print("-" * 75)
if duplicate_count > 0:
print(f"⚠️ 清理完毕:共处理 {duplicate_count} 组重复文章,成功删除 {deleted_count} 篇旧文章。")
else:
print(f"🎉 检查完毕:没有发现需要清理的重复文章。")
api_session.close()
if __name__ == "__main__":
clean_duplicate_posts()
6. 清除karakeep中收藏的过期水木论坛帖子
删除karakeep中n天以前收藏的newsmth.net帖子
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
import time
import logging
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from datetime import datetime, timezone, timedelta
# ================= 日志配置 =================
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# ================= 配置区域 =================
KARAKEEP_URL = "http://4.9.1.8:303"
KARAKEEP_API_KEY = "ak2_d3a838cf9bb166"
DAYS_TO_KEEP = 15 # 删除多少天之前的收藏 (n天)
SEARCH_KEYWORD = "newsmth.net" # 要清理的网址关键字
BATCH_SIZE = 100 # 全局拉取可适当调大单次数量以加快速度
def create_robust_session() -> requests.Session:
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
allowed_methods=["GET", "DELETE"]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
session.headers.update({
"Authorization": f"Bearer {KARAKEEP_API_KEY}",
"Content-Type": "application/json"
})
return session
def clean_expired_bookmarks():
now = datetime.now(timezone.utc)
threshold_date = now - timedelta(days=DAYS_TO_KEEP)
logger.info(f"🚀 任务启动: 将进行全库遍历,清理早于 {threshold_date.strftime('%Y-%m-%d %H:%M:%S UTC')} 的 '{SEARCH_KEYWORD}' 书签")
# 【核心修改】:改用全局列表接口,彻底绕过搜索接口的数量截断限制
list_endpoint = f"{KARAKEEP_URL}/api/v1/bookmarks"
expired_bookmarks_to_delete = []
seen_ids = set()
total_scanned = 0
pull_count = 0
cursor = None
with create_robust_session() as session:
# ================= 阶段一:全库深度遍历 =================
logger.info("🔍 [阶段 1/2] 正在绕过搜索限制,执行全库数据拉取...")
while True:
pull_count += 1
# 仅使用游标进行翻页,不再使用搜索关键字 q
params = {"limit": BATCH_SIZE}
if cursor:
params["cursor"] = cursor
try:
response = session.get(list_endpoint, params=params, timeout=15)
response.raise_for_status()
data = response.json()
bookmarks = data.get("bookmarks", [])
except requests.exceptions.RequestException as e:
logger.error(f"❌ 请求 KaraKeep API 失败: {e}")
sys.exit(1)
if not bookmarks:
break
for bm in bookmarks:
bm_id = bm.get("id")
if not bm_id or bm_id in seen_ids:
continue
seen_ids.add(bm_id)
total_scanned += 1
# 【核心逻辑】:在本地 Python 进行关键字严格过滤
url = bm.get("content", {}).get("url", "")
if SEARCH_KEYWORD not in url:
continue
title = bm.get("title") or bm.get("content", {}).get("title") or "未命名书签"
created_str = bm.get("createdAt") or bm.get("created_at")
if not created_str:
continue
try:
if created_str.endswith('Z'):
created_str = created_str.replace('Z', '+00:00')
created_date = datetime.fromisoformat(created_str)
if created_date.tzinfo is None:
created_date = created_date.replace(tzinfo=timezone.utc)
formatted_time = created_date.strftime('%Y-%m-%d %H:%M:%S')
logger.info(f"📄 提取到匹配书签: [{formatted_time}] {title}")
# 判定是否过期
if created_date < threshold_date:
expired_bookmarks_to_delete.append((bm_id, title, created_date))
except Exception as e:
logger.error(f"解析书签时间异常 (ID: {bm_id}): {e}")
# 获取下一页游标
next_cursor = data.get("nextCursor") or data.get("cursor") or data.get("next_cursor")
if not next_cursor:
break
cursor = next_cursor
time.sleep(0.3)
logger.info(f"✅ 全库扫描完毕。历经 {pull_count} 次拉取,共排查了 {total_scanned} 条底层数据。")
logger.info(f"📌 锁定 {len(expired_bookmarks_to_delete)} 个 '{SEARCH_KEYWORD}' 过期书签准备清理。")
# ================= 阶段二:执行精准删除 =================
if not expired_bookmarks_to_delete:
logger.info("🎉 当前没有需要清理的过期书签,任务完成。")
return
logger.info(f"💥 [阶段 2/2] 开始执行删除操作(共 {len(expired_bookmarks_to_delete)} 条)...")
total_deleted = 0
for bm_id, title, created_date in expired_bookmarks_to_delete:
try:
delete_endpoint = f"{KARAKEEP_URL}/api/v1/bookmarks/{bm_id}"
del_response = session.delete(delete_endpoint, timeout=10)
if del_response.status_code in (200, 204):
logger.info(f"🗑️ 成功删除书签: [{created_date.strftime('%Y-%m-%d')}] {title} (ID: {bm_id})")
total_deleted += 1
else:
logger.error(f"⚠️ 删除失败,ID: {bm_id}, 状态码: {del_response.status_code}")
time.sleep(0.2)
except Exception as e:
logger.error(f"删除请求异常 (ID: {bm_id}): {e}")
logger.info(f"🎉 清理任务彻底完成!本次共清除了 {total_deleted} 条过期收藏。")
if __name__ == "__main__":
try:
clean_expired_bookmarks()
except KeyboardInterrupt:
logger.info("\n🛑 用户手动中断了程序。")
sys.exit(0)
7. 定时任务
crontab -e*/3 * * * * /usr/bin/python3 /root/data/mail_list.py > /root/data/mail_clean.log 2>&1
*/5 * * * * /usr/bin/python3 /root/data/karakeep_smth_forward.py > /root/data/karakeep_smth_forward.log 2>&1
0 8 * * * /usr/bin/python3 /root/data/karakeep_smth_clean.py > /root/data/karakeep_clean.log 2>&1
0 5 * * * /usr/bin/python3 /root/data/mail_merger_to_halo.py > /root/data/mail_merger_to_halo.log 2>&1
0 6 * * * /usr/bin/python3 /root/data/mail_to_halo.py > /root/data/mail_to_halo.log 2>&1
0 7 * * * /usr/bin/python3 /root/data/halo_duplicates.py > /root/data/halo_duplicates.log 2>&1